
Organizations today manage increasingly complex data ecosystems where data flows through multiple systems and undergoes numerous transformations. With Amazon Redshift, a fully managed data warehouse service, you can analyze petabytes of data across your data warehouse, operational database, and data lake. However, as your data pipelines grow more sophisticated, tracking how data moves and transforms becomes challenging. You need visibility into your data's journey – from source to destination – to maintain data quality, ensure compliance, and make informed business decisions.
Select Star is an automated metadata context platform that automatically analyzes and documents your data to provide you with a single source of truth for data. It provides features such as data catalog, lineage, usage analysis, and AI assistants to help data teams govern and manage their data effectively. Select Star serves as a co-pilot for data teams, assisting in data governance, data migration, self-service analytics, data democratization, and cost optimization initiatives. The platform allows users to easily organize and govern their data, making it simple for everyone to find the right data for their needs.
Amazon Redshift is a fully managed data warehouse service that lets you analyze petabytes of data across your data warehouse, operational database, and data lake. As organizations build increasingly complex data architectures with Amazon Redshift at their core, they face the challenge of tracking how data flows through multiple systems and transformations. Without clear visibility into these data movements, it becomes difficult to maintain data quality, ensure compliance, and make informed business decisions.
This post shows you how to implement column-level data lineage for Amazon Redshift using Select Star. You'll learn how to gain detailed visibility into your data transformations, understand dependencies, and track data movement across your warehouse environment. By following these steps, you can better govern your data, quickly troubleshoot issues, and confidently manage changes to your data models.
Column-level data lineage: A crucial tool to understand data
When you manage data in Amazon Redshift, you need to track how your data moves and changes throughout your systems. Data lineage helps you do this by creating a detailed map of your data's journey: from where it originates, through its transformations, to where it's used. With column-level lineage, you can track individual data elements as they flow through your system, helping you maintain data integrity, ensure compliance, and derive accurate insights.
Think of data lineage as your data's story in Amazon Redshift. It shows you where your data comes from, how it transforms as it moves through your systems, and where your teams ultimately use this data in their workflows. This visibility becomes particularly valuable when you're troubleshooting data quality issues or planning changes to your data models. For example, if you find an inconsistency in a report, you can trace the data back to its source to identify where the issue originated. Similarly, before modifying a source table, you can see exactly which downstream reports and analytics might be affected by your changes.
This comprehensive view of your data's journey helps you work more efficiently with Amazon Redshift. You can troubleshoot issues faster by quickly identifying the root cause of data discrepancies. You can make changes to your data models with confidence, knowing exactly what downstream impacts to expect. For compliance requirements, you can easily track sensitive data throughout your system. Most importantly, you can understand the complex dependencies between different data assets, helping you maintain a reliable and efficient data ecosystem.
The Benefits of Data Lineage
When you use data lineage with Amazon Redshift, you gain transparency into your data models that helps you work more efficiently. Instead of manually investigating each step in complex pipelines when issues arise, you can quickly trace problems to their source by following the lineage map. For example, if you notice incorrect values in a dashboard, you can follow the data's path backward through your transformations to find exactly where the discrepancy began.
Data lineage also helps you understand how changes to your data models affect your entire system. Before you modify a table, schema or update a transformation pipeline, you can see exactly which downstream reports and analytics will be impacted. This visibility helps you prevent unexpected disruptions and plan your updates strategically. For instance, if you need to modify a frequently used source table, you can identify all dependent dashboards and notify the relevant teams before making the change. This proactive approach helps you maintain data reliability while confidently evolving your Amazon Redshift environment.
Data Lineage with Select Star
With Select Star, you can visualize and understand how data flows through your Amazon Redshift environment. The lineage feature automatically maps relationships between your data assets by analyzing SQL statements from your connected data sources. This gives you a clear view of where your data comes from and where it flows, helping you understand dependencies across tables, columns, and dashboards. When you plan changes to your data assets, you can quickly see how these changes might affect your entire data environment.
Select Star's lineage view provides four ways to explore your data relationships:
- Upstream: Shows the immediate upstream dependencies in a tree hierarchy, helping you trace where your data originates
- Downstream: Shows the immediate downstream dependencies in a tree hierarchy, letting you see what depends on your data
- Downstream Dashboards: Shows all dashboard dependencies downstream with extended information like Top User and dashboard Popularity, helping you understand data consumption
- Explore: Shows an advanced lineage graph that allows navigation of data flow at the column level, giving you the most detailed view of your data relationships

Getting Started with Select Star and Redshift
By setting up column-level lineage with Select Star, you can gain detailed insights into your Amazon Redshift data environment. This feature helps you understand exactly how your data flows and transforms across your warehouse. In the following sections, you'll learn how to configure column-level lineage for your Amazon Redshift cluster. After completing these steps, you'll be able to track data relationships at a granular level, helping you better manage your data assets and understand their dependencies.
Step 1: Create a new data source
- Go to Select Star Settings and click on "Data" in the sidebar.
- Click "+ Add" to create a new Data Source.
- Choose "Redshift" as the Source Type and provide the required information, including
- Display Name: This value is Redshift by default, but you can override it if desired.
- Cluster Name: The name of your AWS Redshift cluster in the AWS management console. Also known as "Cluster identifier" by AWS.
- Database: The name of the database in AWS Redshift you've given us access to.
- AWS Region: ID of the AWS region where the cluster was created. For example us-east-2,us-west-1, eu-central-1
- Click Connect
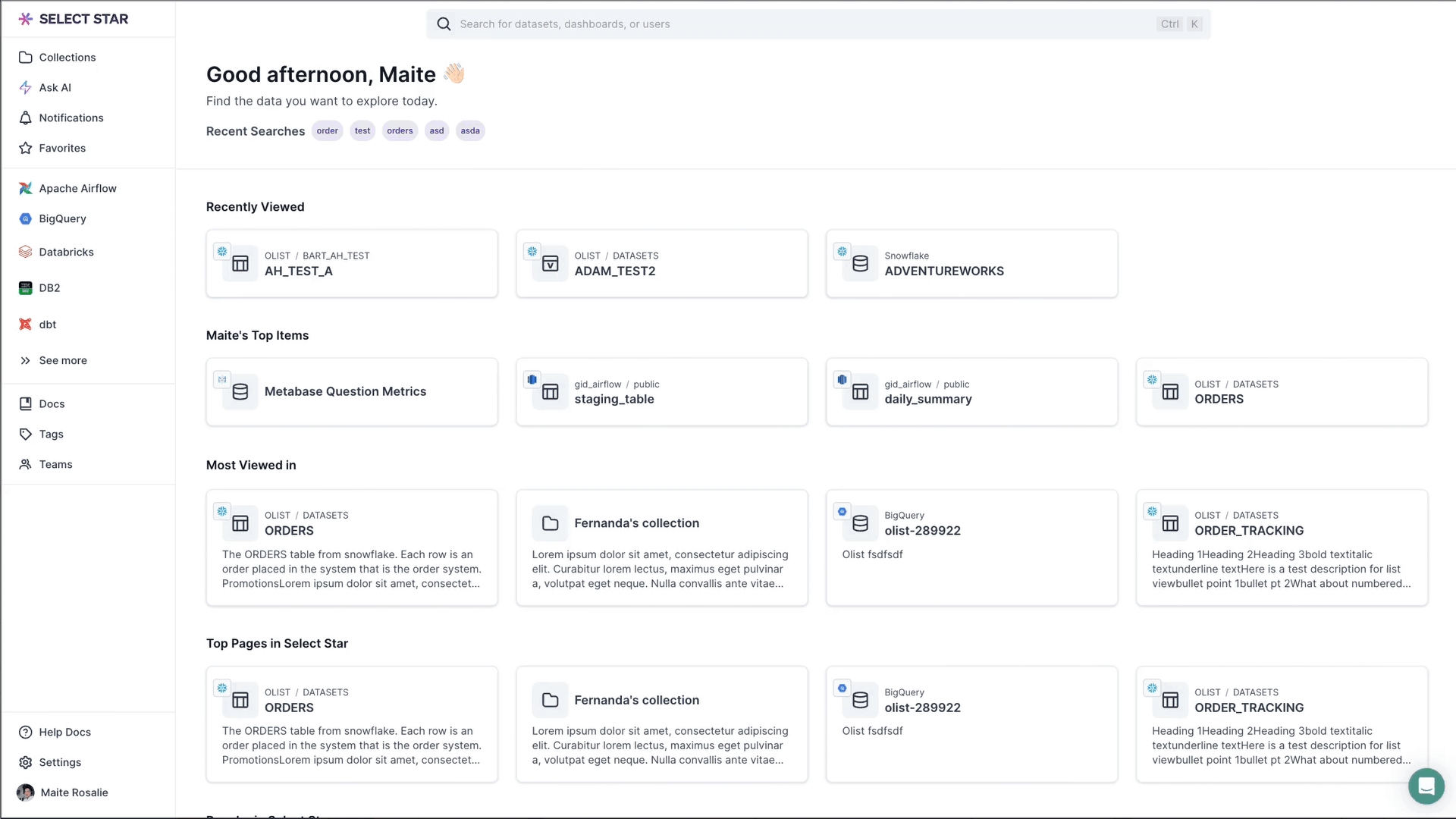
Step 2: Set up CloudFormation stack
Select Star recommends using AWS CloudFormation for a safe and auditable integration setup.
- A form will be displayed. Click the "Open CloudFormation" button. This will open a new window to the AWS Management Console and proceed to create the CloudFormation stack. Ensure you're logged into the correct AWS account where your Redshift cluster resides.
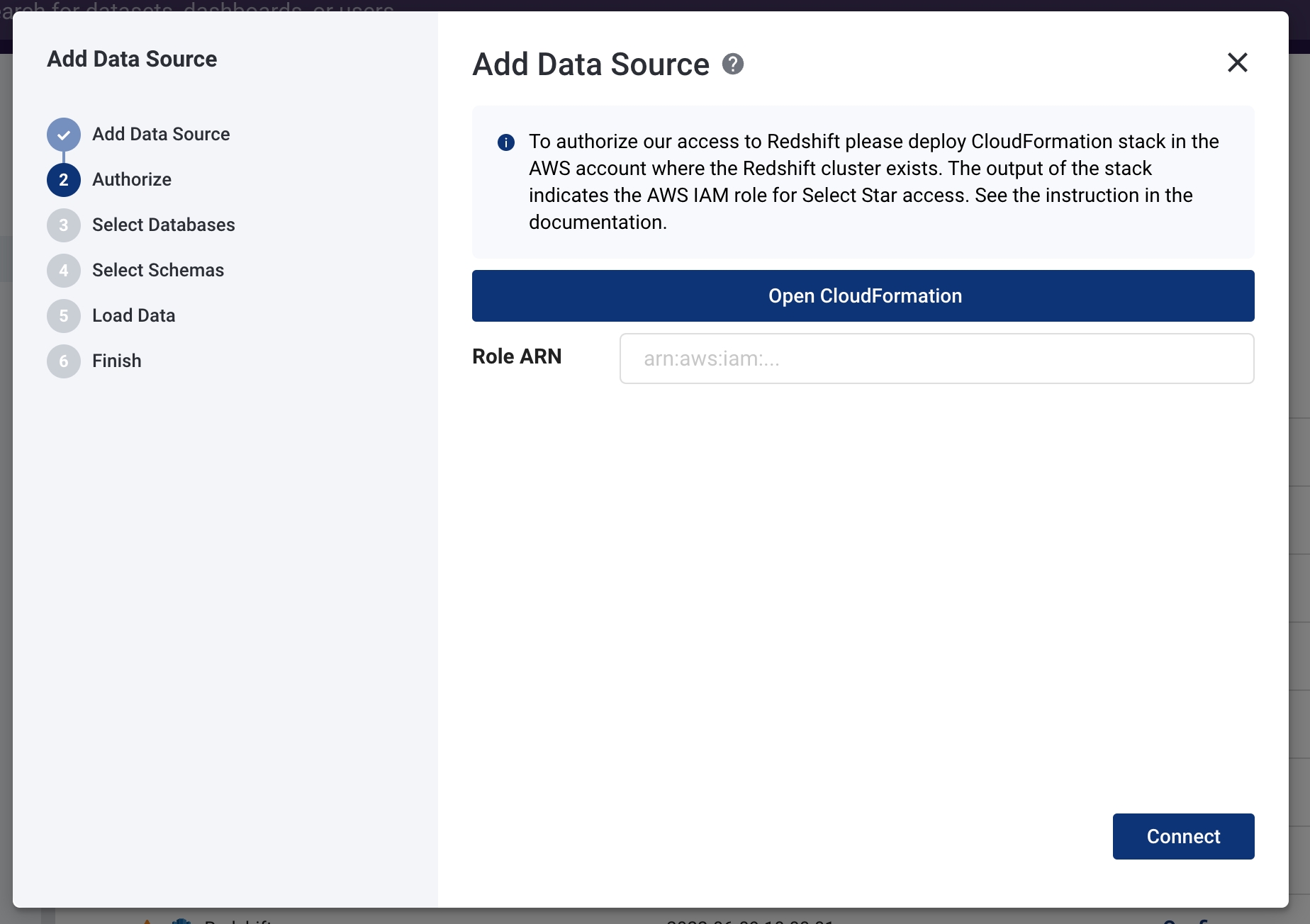
- On the Create Stack form, enter the required parameters:
- Amazon Redshift cluster name
- Comma-separated list of database names
- Your database username (this will only be used to create a dedicated "select_star" user)
- Also, on the same Create Stack form, set "Configure S3 logging" and "Restart Cluster" fields to "true" for automatic configuration.
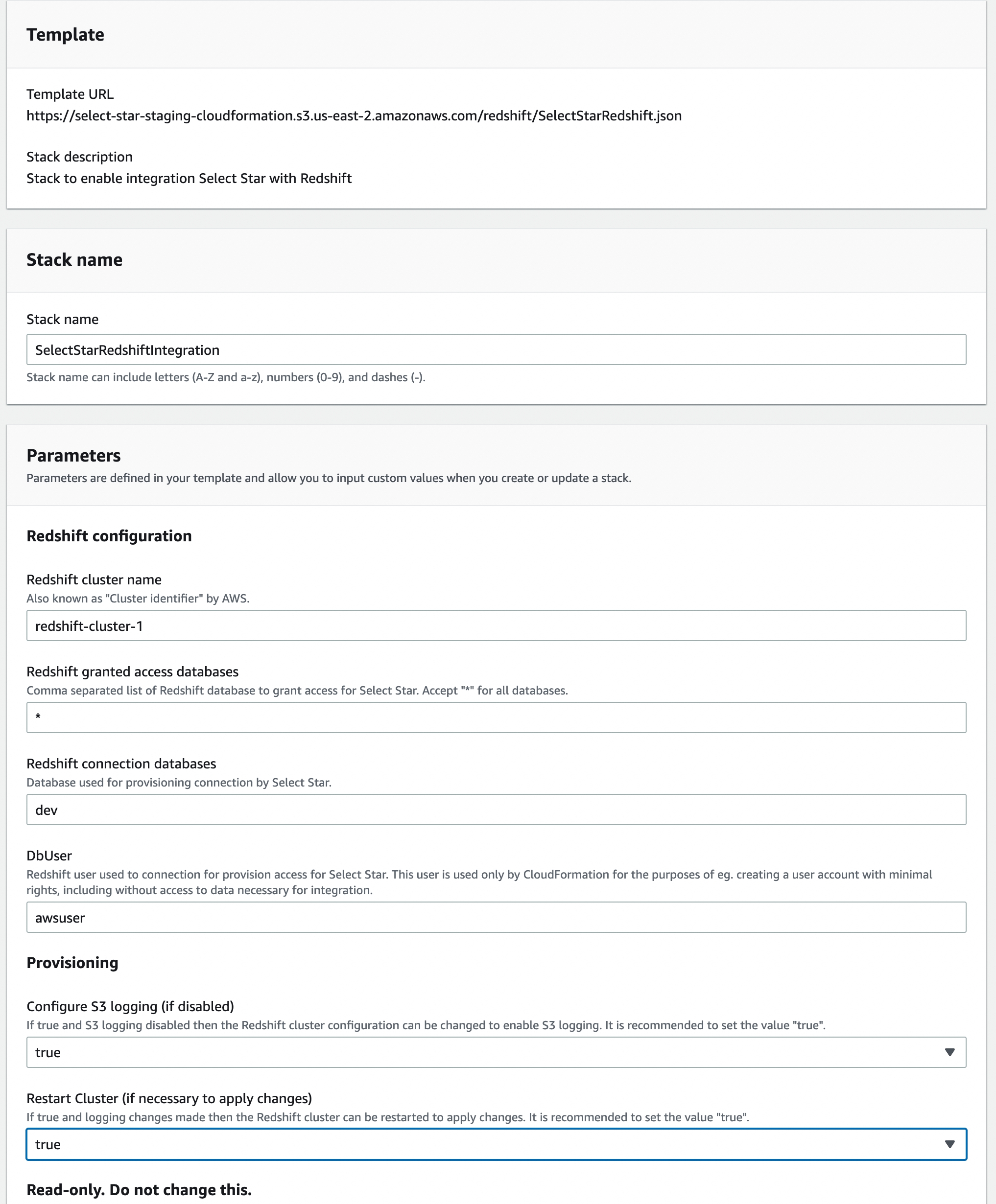
- Review the information carefully. At the bottom of the form, check the box that says "I acknowledge that AWS CloudFormation might create IAM resources."
- Click the "Create stack" button to initiate the process.
- Wait for the stack status to change from "CREATE_IN_PROGRESS" to "CREATE_COMPLETE" in the Stack info tab. This typically takes about 5 minutes and you will need to refresh the tab to see the progress.
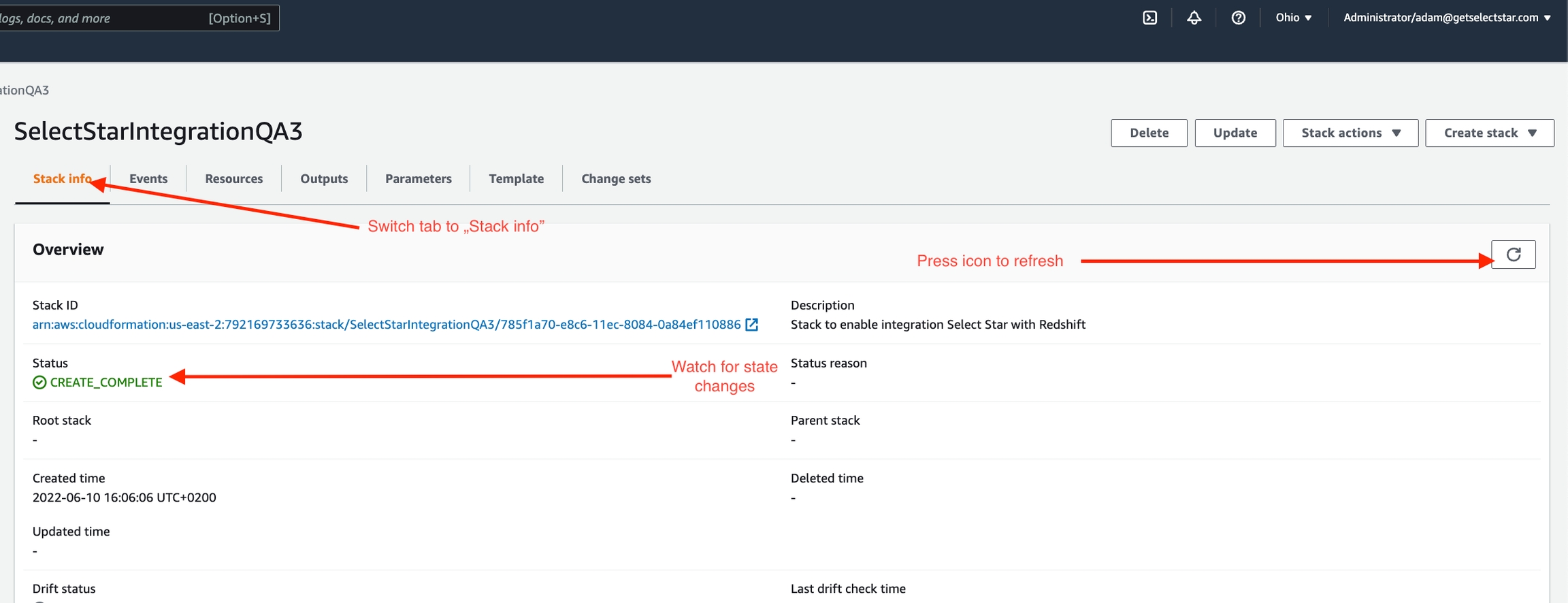
Step 3: Confirm authorization
- Once the CloudFormation stack is created, copy the Role ARN from the Outputs tab.
- Return to Select Star and provide the Role ARN in the authorization form.

Step 4: Select databases and schemas
- Choose the databases and schemas you want to load into Select Star.
- Select Star will generate lineage for the selected databases and schemas.
After completing these steps, Select Star will begin syncing your Redshift metadata. Within 24-48 hours, you'll be able to explore column-level lineage for your Redshift environment directly within the Select Star platform.
Future-Proof Your Governance Strategy with Data Lineage
Column-level data lineage for Amazon Redshift with Select Star makes it easier to see and understand how data flows through your warehouse environment. In addition to Amazon Redshift, Select Star integrates with AWS services like AWS Glue and Amazon Quicksight, as well as widely used databases and business intelligence tools. Together, these integrations provide a complete view of your data ecosystem.
With column-level lineage in place, your team can govern data assets more effectively and simplify compliance across the organization. This visibility makes it easier to plan data changes, understand dependencies, and quickly resolve issues by tracing them back to their source. As your data environment scales, having this clear picture of data movement becomes essential for maintaining quality, reliability, and trust in your analytics.
To get started with Select Star for Amazon Redshift, you can visit AWS Marketplace to deploy the solution today. If you'd like to see the features in action, schedule a demo with our team.







